July 9th, 2023, to be more specific
Up until January of this year, Tangerine has largely been a single-threaded C++ program with the singular purpose of constructing SDF evaluator trees and processing them into an optimized intermediary form to be used for SDF ray marching on the GPU. This was all in pursuit of some vague goals of building a general purpose game engine.
While recovering from a major illness back in January, I came to a deep appreciation of how fragile and ephemeral the thread of my own life is and of the limitations of pursuing personal research in my free time when the vast majority of my waking hours and what remains of my good health must be rented out so I can pay bills, and so on. My motivation to keep working on Tangerine's old renderer is dead now, and no mourners showed up for the funeral. However, it turns out that being incapacitated for over a month by a disease that has killed 7 million people and continues to hospitalize and kill people every day was great for my creativity, much in the way that a forest fire clears the ground and (among other things) gives opportunity for new life to grow. Tangerine's old renderer now has the name "Shape Compiler", because there is now a need to differentiate it from a new one.
Since then I have been slowly working on a new renderer for Tangerine. I've arbitrarily named this new renderer "Sodapop", because it is light and bubbly and tends to cheer me up. I'm intentionally glossing over a significant amount of rational and problem space here, but the goal of Sodapop is to be The World's Most Affordable SDF Renderer, with something of an unhinged and vaguely threatening tone intended in the emphasis of those words. I'm attempting to minmax the crap out of the frame rate on the theory that doing so will eliminate a wide variety of problems that vex the old renderer and make the remaining problems much easier to solve. To get there, I'm rigorously adhering to this fairly boring observation as an immutable rule: the absolute fastest way to draw anything on the vast majority of 3D graphics hardware ever created is to violently ram opaque triangles through at it maximum velocity.
Sodapop currently beats the pants off of Shape Compiler at rendering performance by a mirth-inducingly large margin for all models that Sodapop is currently able to load, and it does so with these two exciting shaders:
This vertex shader...
And this fragment shader...
Sodapop works like this:
Now here's the fun part: only step 4 has to run synchronous with the GPU, and everything else can be moved into a thread pool for asynchronous processing.
Based on my experimentation so far, I believe Sodapop is likely to be trivially portable to any computer with a strong enough CPU (at least 1.5 GHz of processing power and two or more threads of execution) and some variety of 3D raster hardware, but the exact requirements will depend on the needs of the application.
Implementing this new renderer has required a number of supporting changes to Tangerine, all of which are active works in progress at this time of writing:
Sodapop requires a robust and fast means of extracting triangle meshes from SDF evaluator graphs. Currently I'm using a fork of naive-surface-nets, which is a library that implements the meshing algorithm of the same name. One of the two implementations of the algorithm in the original library is optimized around parallel execution with C++'s std::for_each form.
Tangerine's fork of this library carves up this parallelized implementation so that it can run using Tangerine's thread pool instead of using the parallel form of std::for_each. This allows it to run cooperatively with Tangerine's other parallel work.
The current meshing implementation performs very poorly as the volume of a model increases. This is fine for now, but it will eventually need to be replaced by a faster algorithm. Ideally the replacement will allow for the mesh to be gradually refined as it is rendered.
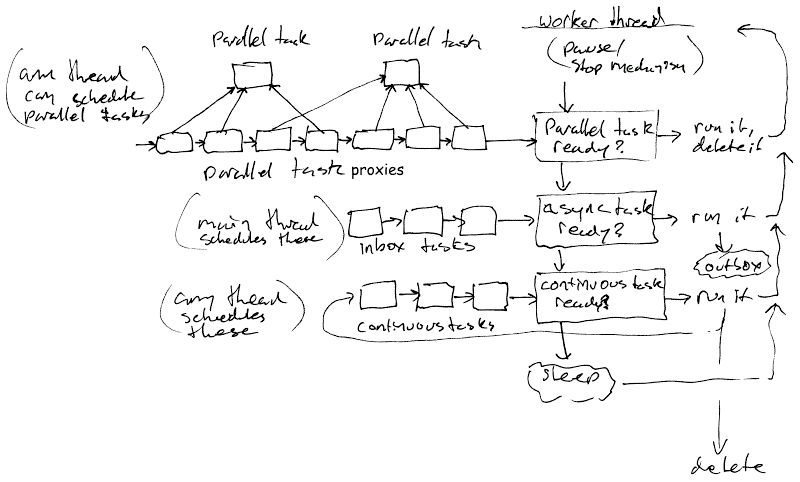
The biggest new thing is Tangerine now has a persistent thread pool with a lockless task scheduling system. The main thread and the thread pool communicate by way of several task queues. These task queues use the atomic multi-producer multi-consumer ring buffer implementation from the excellent atomic_queue library.
The thread pool is currently fed by three queues in order of priority: "parallel", "inbox", and "continuous". The main thread receives tasks from the thread pool by way of two queues: "outbox", and "delete".
Single threaded asynchronous tasks are placed into the inbox, process for a bit on the thread pool, and then are moved to the outbox for finalization on the main thread.
Tasks that are meant to be processed by many threads simultaneously will have multiple task proxies pushed into the parallel queue. These task proxies hold each hold a shared pointer to the original task, which then provides the shared data and functions for the proxies to invoke. A given parallel task is assumed to be a loop that repeatedly processes iterations of a shared work set using an atomic counter until the work set is exhausted. When the last parallel task proxy is exhausted, a completion callback is immediately called once, which is useful for finalization and scheduling follow up work.
Continuous tasks are tasks that run briefly then reschedule themselves until they are no longer relevant. This is where Sodapop's asynchronous lighting work runs.
Finally, the delete queue is for finalizers that must run on the main thread.
This flowchart illustrates how tasks move through a single worker thread in the thread pool:
For the moment, Shape Compiler and Sodapop coexist in Tangerine. Shape Compiler is only supported when OpenGL 4 is supported, but Sodapop currently has an implementation for both OpenGL 4 and OpenGL ES 2.
The implementation for this is very crude. All model instances that share a SDF node graph also share a polymorphic object that is inconsistently called a "drawable" and a "painter", which wraps its rendering intermediaries and so on. The renderers are implemented as a monolithic frame rendering function and corresponding drawable.
The plan is to retire Shape Compiler once Sodapop is able to fully replace it, but this interface will continue to be useful for supporting a broader selection of rendering APIs in the future.
Tangerine previously used a custom reference counting scheme to manage deallocation for the SDF evaluator graph nodes and model instances. This scheme was only suitable for single threaded execution, and so it has since been ripped out in favor of using std::shared_ptr and std::weak_ptr to control object lifetimes. The standard smart pointers were chose on the partial misunderstanding that they are thread safe, but they appear to be sufficient.
In both the old and new memory management schemes, reference counting is effectively an adapter between Lua's memory model and C++'s. Lua scripts (among other things) drive the creation of SDF graphs and the creation of instances of those graphs. Lua's garbage collector in turn releases the references on those structures when they are no longer needed, and C++ in turn deletes those allocations shortly after once it is safe to do so.
This diagram illustrates the basic object ownership graph. Bold arrows indicate where shared references are typically held, and dashed arrows show where weak references are typically held. The main thread also holds additional references that are not pictured, but should not be contradictory to the indicated life cycle.
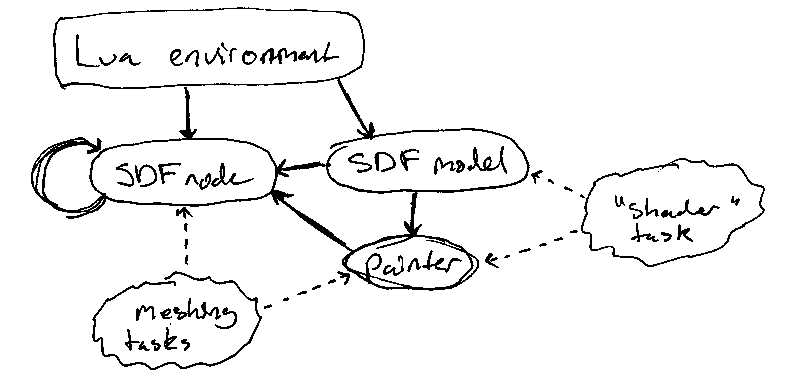
Note that SDF nodes are a tree data structure. No node holds a reference to itself, and the SDF node graph has no cycles.
Finally, the meshing and "shader" task groups correspond to tasks that are executed by the thread pool. These tasks lock their weak refs when they run, and so it is possible for the objects they point to to be deleted on a worker thread after the task that locked it releases it. For the most part this is fine, but a painter's GPU resource handles must jettison themselves to the delete queue for deferred deletion on the main thread in this situation.
As a savvy reader, you may have noticed that this article has very to say about any actual rendering. Instead, I have outlined several structural problems that have impeded progress on the renderer itself. Most of these have ok-ish temporary solutions.
In particular, the provisional meshing system has the most potential to stand in the way of progress on the renderer. Currently it generates a set of flat arrays for the different vertex properties, which the concurrent "shader" tasks then operate directly to generate new vertex color arrays. This creates a critical section between the task graph and the main thread, because the main thread also has to access these arrays to upload them to the GPU. I'm considering instead switching to a system where the main thread has a shadow copy, which the worker thread sends updates through the outbox queue. I'm unsure if the extra copies or if the potential lock contention will be more expensive at this time.
Another tricky bit, also somewhat pertaining to the meshing system is I eventually want to expand the renderer to perform various ray tracing tasks as part of the vertex color genesis. These would be things like determining which lights currently illuminate a vertex, but also other neat stuff like reflection and transmission. I will probably start by ray tracing AABBs to find applicable evaluator graphs, and then use SDF ray marching on the CPU to find ray hits. However, it might be more sensible to instead ray trace the generated meshes, as that would make it easier to cache information useful for ray bounces, but would also require some kind of acceleration structure for accessing the mesh data.
I believe I am several good nights of sleep away from solving all of the architectural problems and ambiguities outlined above, and so I expect in several months I'll have successfully drilled down to bedrock and